
 One of the biggest challenges in business (or crisis) planning are varying predictions. Even those taking more scientific approaches often find results contradict each other. Common causes for this are:
One of the biggest challenges in business (or crisis) planning are varying predictions. Even those taking more scientific approaches often find results contradict each other. Common causes for this are:
- Underlying data
- Error in underlying assumptions
- Correlation vs causation
- The modelling approach used
However the real challenge often comes as a combination of these. Firstly let’s review each off these causes.
Underlying data
There are typically two sources of data used for planning: experience data and research.
Looking at the COVID19 pandemic as an example, if we wanted to estimate our reproduction or R rate (see our previous article on building a COVID 19 calculator), we could go and ask a sample of people (research), or we could estimate it from the number of “new cases” identified by the hospitals (experience data). Both approaches have their advantages and disadvantages.
Experience data tends to be more complete, i.e. all new hospital cases are recorded so it is based on actual data. It would not, however, include information such as the number of people that think they may have had the virus but chose to stay at home. It can also be subject to errors (i.e. when recording systems are down).
Often models can use a combination experience data and research. For example, asking 10k people and then scaling up the findings to represent the population i.e. 60m. To do this you need an estimate of the number to roll up to (i.e. where does the 60m come from?). We may also need to weight the sample (in case the survey had a skew).
Another reason for a difference in predictions caused by the underlying data is the actual definitions used. For example, if we re-defined a model to “predict the R rate leading to a hospital visit” we may be able to rely solely on experience data.
Definitions can cause all sorts of troubles, for example the definition of deaths related to COVID 19 was changed between March and May 2020 to reflect care home deaths. This means that anyone using the experience data would need to account for that, using an assumption.
Error in underlying assumptions
It takes a week or two for people to develop COVID19 symptoms. So if we wanted to estimate the number of new cases in any given week, we may want to build that up from a multiple of factors or assumptions:
The actual model or equation could be:
New cases = How many people had the virus the week before * R rate
i.e. if there were 10k people with it and they each gave it to 2 people (R=2), the new cases are 20k.
But, how do we estimate “How many people had the virus the week before”?
Parking issues with varying results in the underlying data to one side, say we could agree the following assumptions were accurate within 10%:
- The number of cases submitted to hospital: 10k
- Only 1 in 10 people who have the virus go to hospital
- An additional 20% of people will fall into the following week
Adding these together we get: 10k * 10 + 20%( or * 1.2) = 120k
However, if each of these assumptions are 10% out the answer could vary between 87k & 160k cases a range of over 70k!
- If everything is under estimated by 10%: 11k people * 11 * 22% = 159,720
- If everything is overestimated by 10%: 9k people * 9 * 18% = 87,480
Correlation vs causation
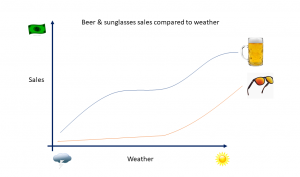 Moving away from the pandemic and drawing on a commercial scenario for this, in the summer months a retailer may find an increase in sales of beer and sunglasses. People drink more and spend more time outside as it gets hotter.
Moving away from the pandemic and drawing on a commercial scenario for this, in the summer months a retailer may find an increase in sales of beer and sunglasses. People drink more and spend more time outside as it gets hotter.
This means that beer and sunglasses have some level of correlation in sales, as they are both driven by the same “causation” factor – the weather.
Why is this important?
Based on the above scenario, we know that typically as you sell more sunglasses you also sell more beer. Would it therefore be fair to say that a promotion or advertising on sunglasses is going to result in more beer sales? Or vice versa? … No, because the underlying cause is the weather.
A key point then is that the challenge with any model or situation is to really understand for any variable whether it is actually causing a change.
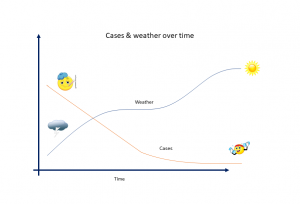
Returning to COVID 19, it was considered whether hotter temperatures would “kill off” the virus.
If you take a view of cases vs the weather since the lockdown, you may see a relationship like the one to the left. It looks as if improved weather has led to a drop in cases.
But when you look at other data, such as infection rates in other (hotter) countries then it becomes clear that weather is not a driver. Therefore we should not consider it in any predictions.
Modelling approach
Statistical programs like SPSS, SAS, or R, have a range of modelling approaches that can be deployed. Regression models, CHAID models, or neural networks are just a few examples.
Typically these approaches are just used to process the data, and automatically test and calculate assumptions – ultimately to find suitable assumptions.
AI and machine learning (ML) typically use these processes, but in an even more automated way. As a side point. most AI or ML projects fail because of the three challenges outlined above. Whilst all of these approaches have their place, they can also often lead to different results.
How to see the wood through the trees

Without full access to underlying data, or understanding challenges that lie behind a model it is very difficult to say what is right and what is wrong.
It is also clear how the smallest change in understanding or assumption can have huge effects.
So, whether it’s data for your own business planning, or review information provided from other data sources, here are a few initial points to look at:
- What are you actually trying to achieve? I.e. what is the definition of the result or outcome you seek?
- What do you need to estimate this?
- What data do you have and what assumptions are required for that estimate?
- Consider what is the best/worse case if these are wrong
Can we help?
If you would like support with planning your business, or are questioning some of the models and forecasts you are seeing, then we would love to hear from you.
Our team have supported a wide range of businesses including…
- predicting underwriting outcomes for life insurance,
- predicting next best action or life time value for marketing teams
- forecasting demand for materials in manufacturing
and much more.
Do get in touch if we can help.
